2 Data
2.1 Description
The data source we use for this project is the National Assessment of Educational Progress (NAEP). The NAEP is a federal program under the US Department of Education that administers standardized tests typically every four years to test students’ reading and mathematics skills. The data we will use for this project is collected from the results of NAEP assessments administered from 1978 onwards. As the national evaluation is typically administered every four years, the frequency of the data is every four years. The data can be downloaded in a .xls format from the NAEP website, and we will convert them to a .csv format. The data can be downloaded by all years from 1978-2022 and by any of the following variables: all students, region of the country, gender, disability status (including 504 plan), disability status (excluding 504 plan), status as an English learner, race/ethnicity, public or private school, public or nonpublic school, National School Lunch program eligibility, and school location. For this project, we will focus on the following demographic variables: region of the country, gender, disability status, status as an English learner, race/ethnicity, National School Lunch program eligibility, and school location. Because the data can only be downloaded by one variable at a time, we will have to import separate CSV files for each of these datasets and then join them. We also know that data for all these demographics is not available for all years, so we anticipate narrowing the scope of our project in terms of time.
https://www.nationsreportcard.gov/ndecore/xplore/ltt
2.2 Missing value analysis
2.2.1 Mathematics Data
2.2.1.1 Disability
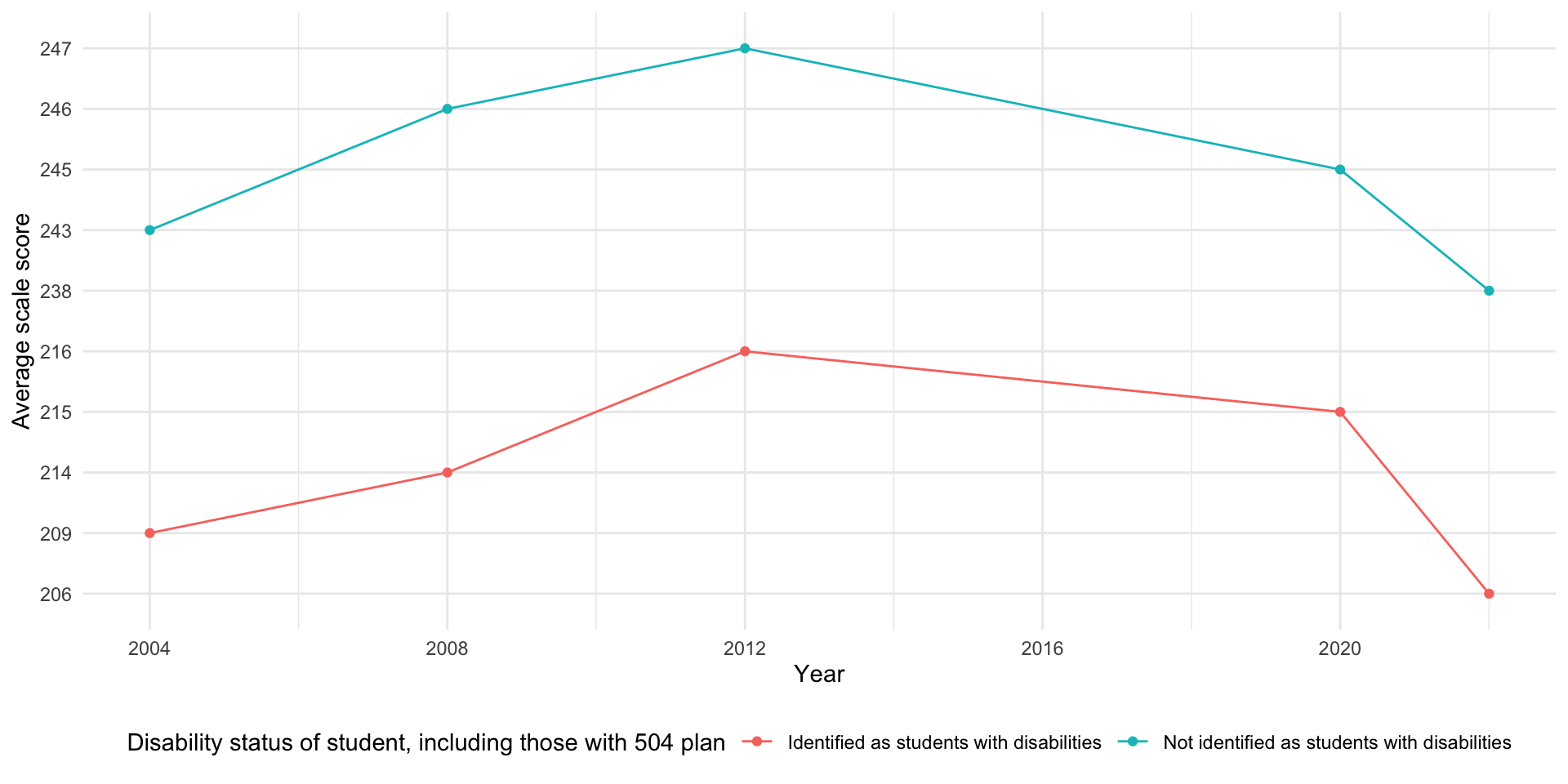
[1] "Total number of missing values in the disability dataset: 18"The data appears to be collected roughly every four years. However, data in 2016 is missing for the disability category here, as well as in most of the other categories. The data begins being recorded in 2004. There are no records prior to that year either due to insufficient reporting standards or not being available.
2.2.1.2 Gender
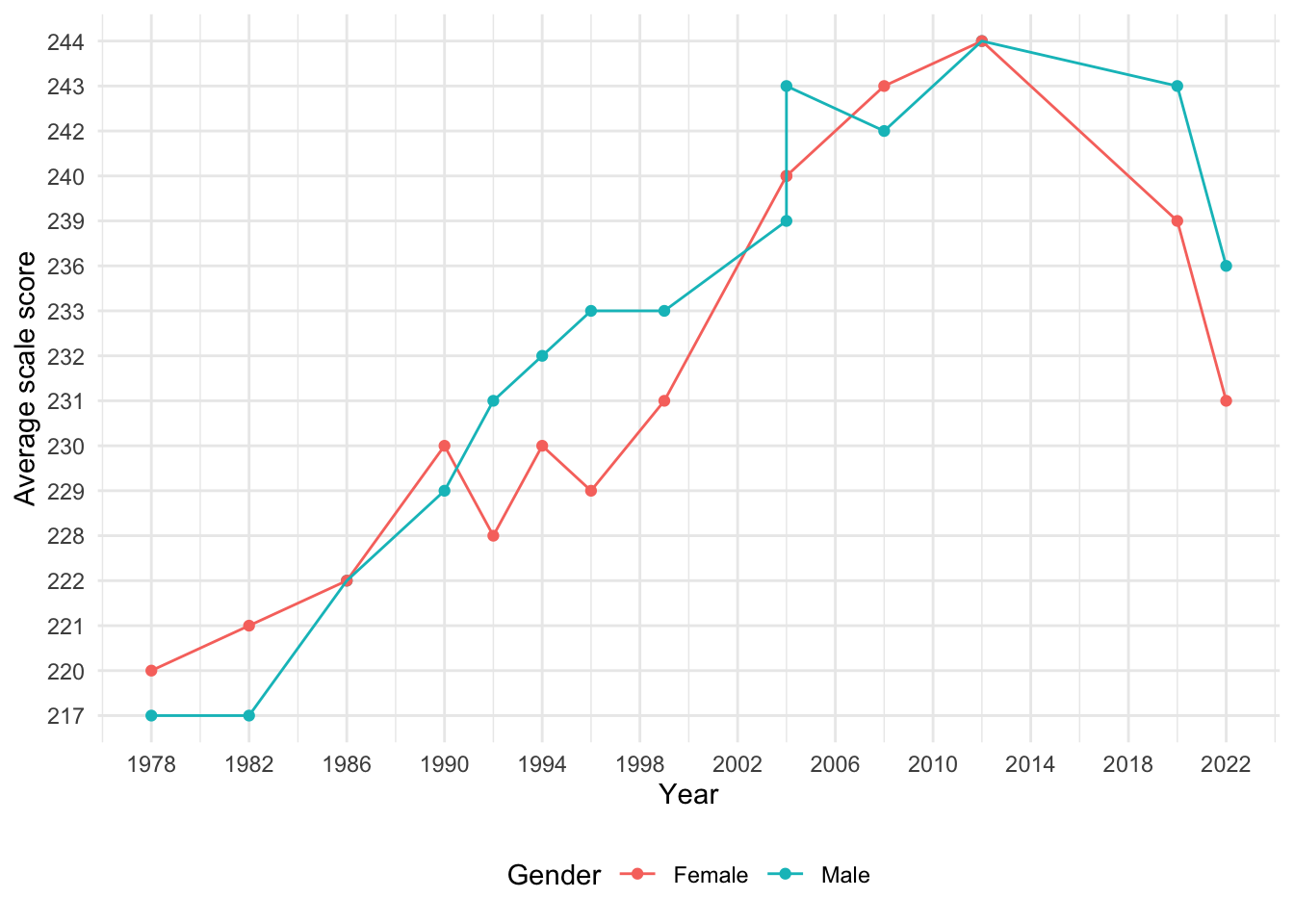
There appears to be missing data in 2016 in the gender category as well. There is also a vertical segment in the Male timeseries which is due to a transition from an “original” exam to a new exam version. The vertical segment reflects recorded values for the two versions of the exam in the same year. The scores for Female students were equivalent in both versions, so there is no vertical segment in that particular line graph.
Other than 2016, there is no missing data set throughout 1978-2022. The fact that data is available for over four decades suggests that gender data is likely a critical component of the dataset and historically it has been prioritized compared to other metrics.
2.2.1.3 National School
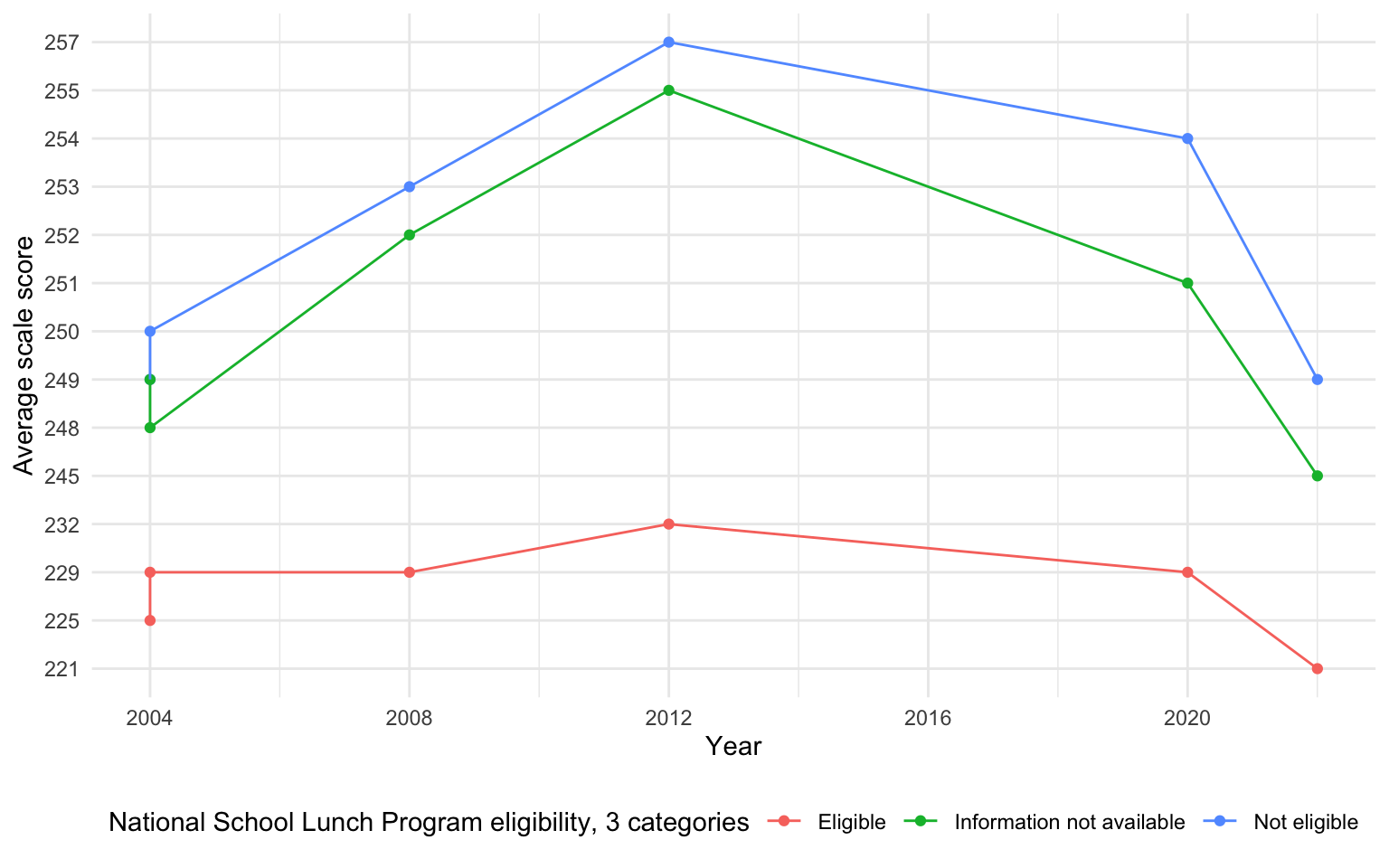
[1] "Total number of missing values in the national school dataset: 24"Again we see vertical segments due to the transition between exam versions, and we also see missing data in 2016. Once again, data prior to 2004 is unavailable in this dataset resulting in 24 missing values in the Average Scale Score column.
2.2.1.4 Race Ethnicity
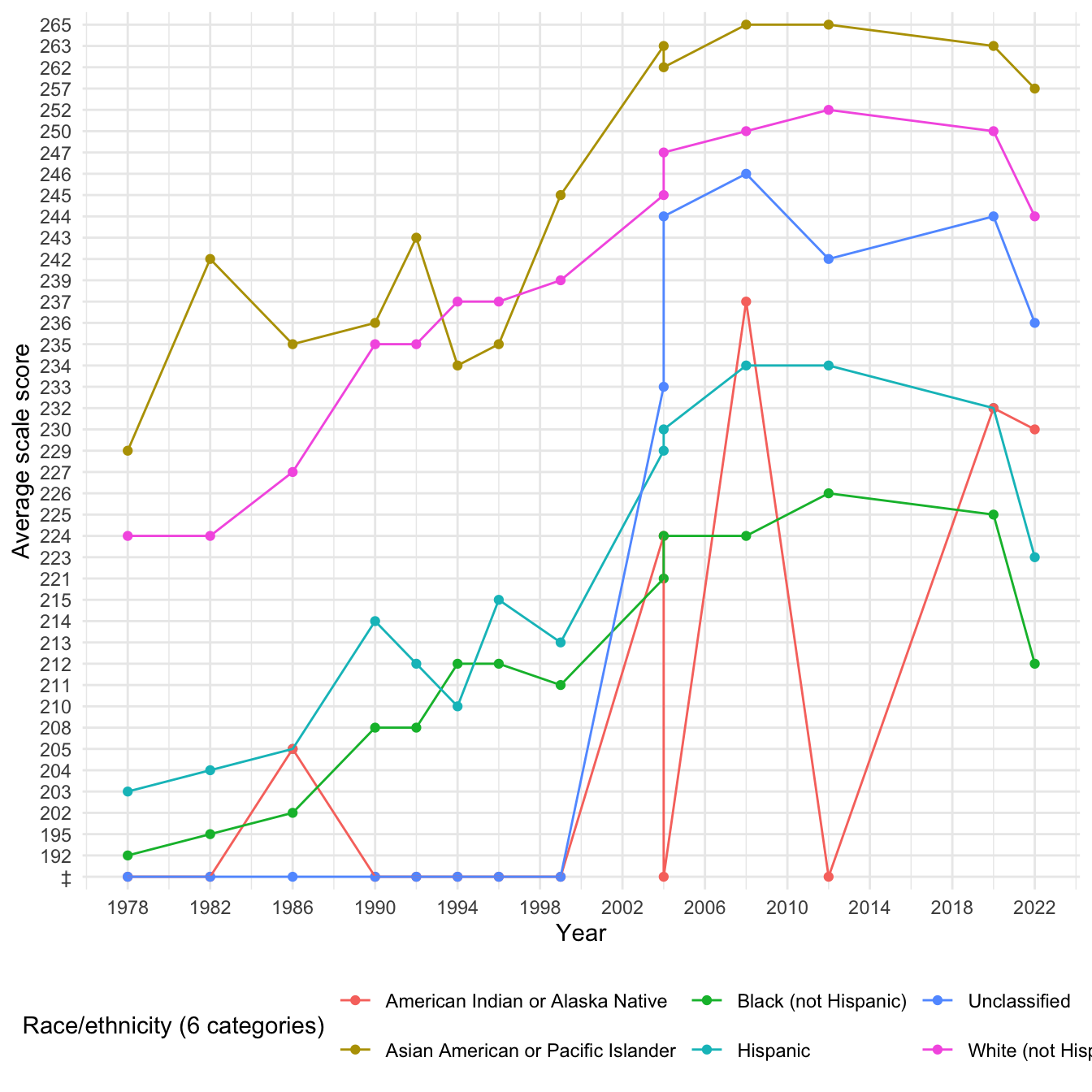
This graph also contains vertical line segments at year 2004, as well as missing data in 2016. Another interesting thing to note here is the special character, which signifies that the reporting standards were not met, at the bottom of the y-axis. This primarily affects the Unclassified and American Indian or Alaska Native students.
[1] "Total number of missing values in the dataset: 17"2.2.1.5 School Region
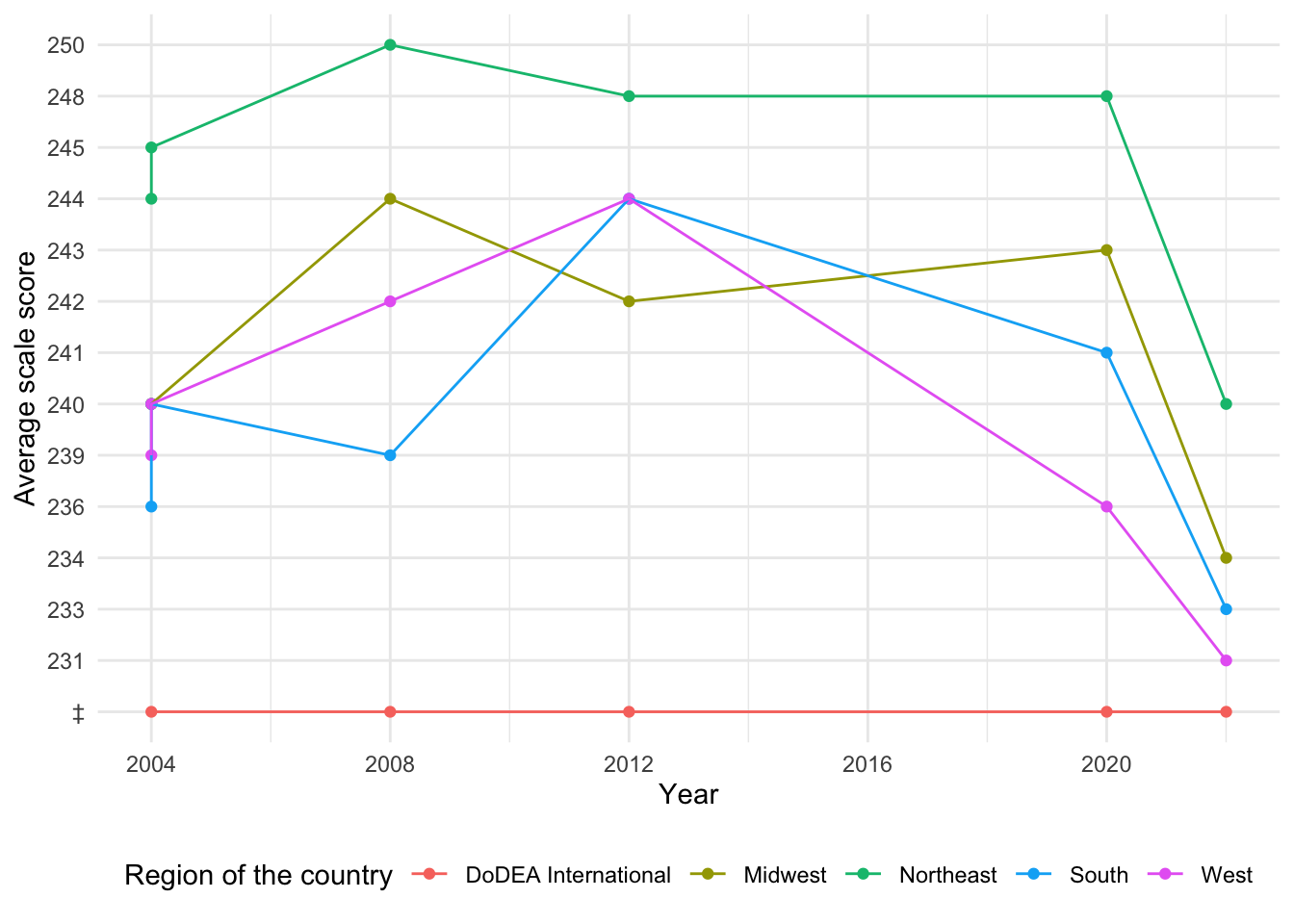
[1] "Total number of missing values in the region dataset: 46"Here we see the same missing data patterns as before: vertical segments at 2004, missing data in 2016, and reporting standards not met for the DoDEA International region of the country. We also have N/A score data for years prior to 2004.
2.2.1.6 School Location
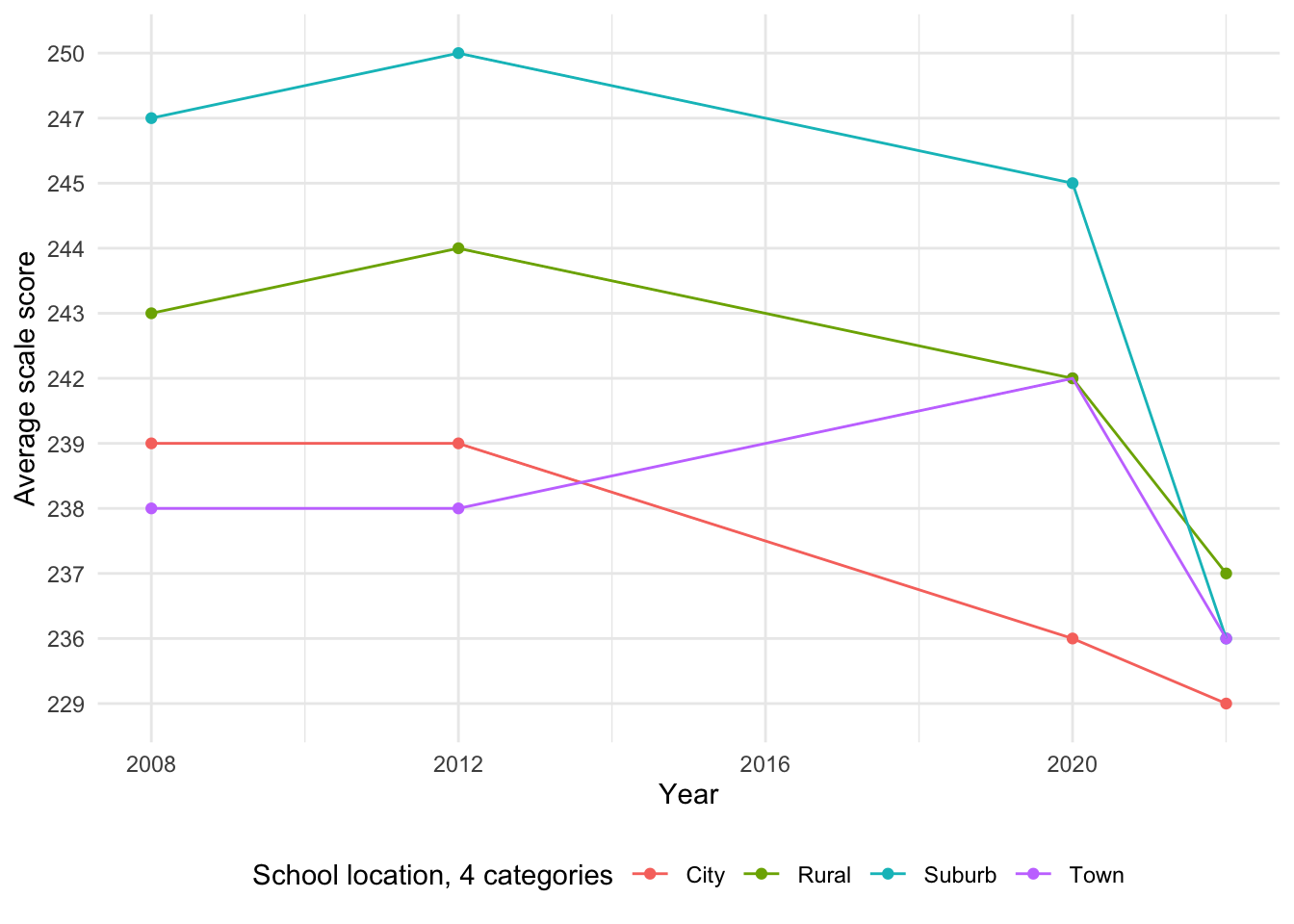
[1] "Total number of missing values in the location dataset: 40"In this category, the only notable observation is missing data in 2016. There are 40 missing score values, starting from 1978 to 2004.
2.2.1.7 Status as English Learner
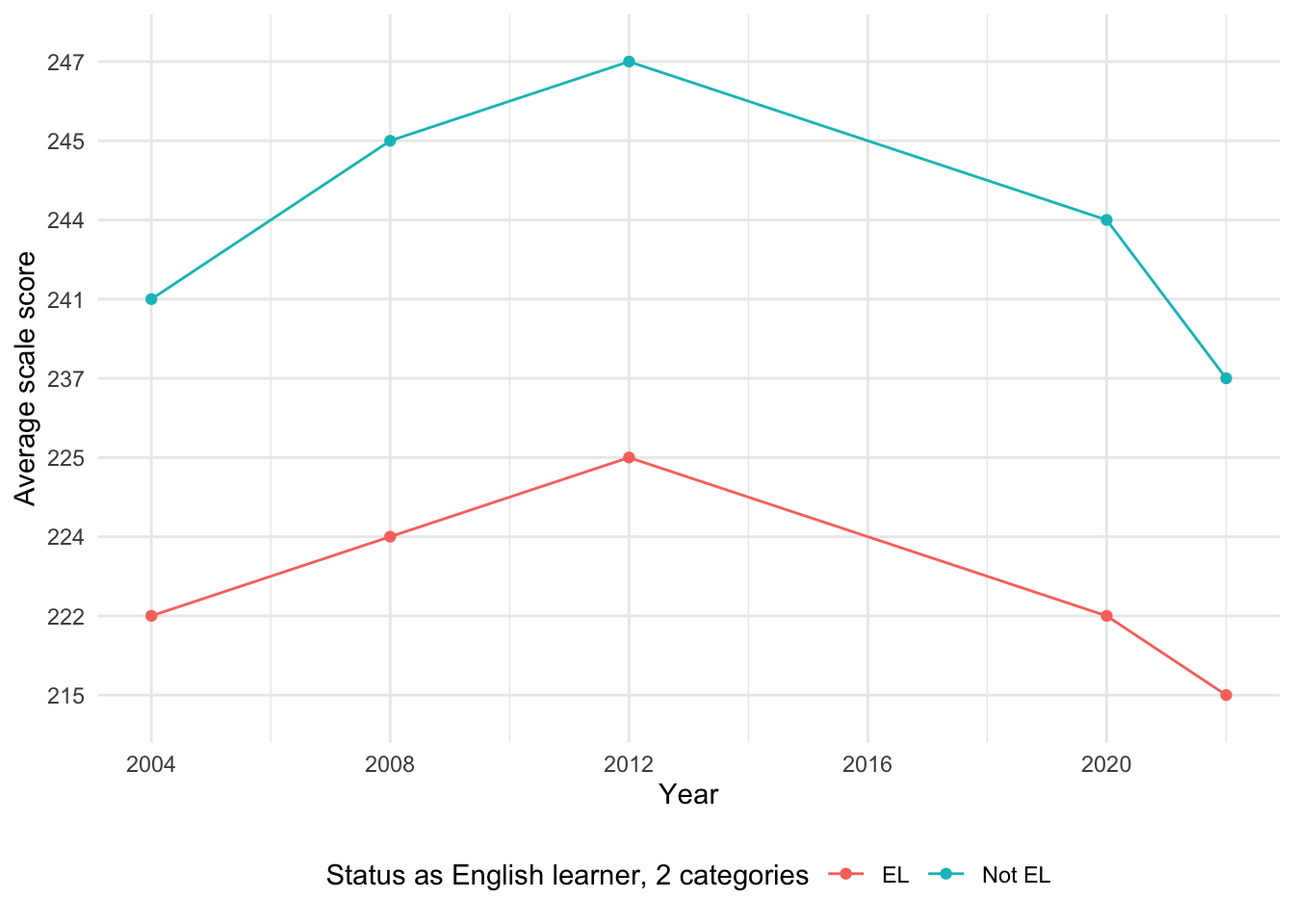
[1] "Total number of missing values in the eng_status dataset: 14"Once again, there is no data for 2016. Prior to 2004 there is no score data.
2.2.2 Reading Data
2.2.2.1 Disability
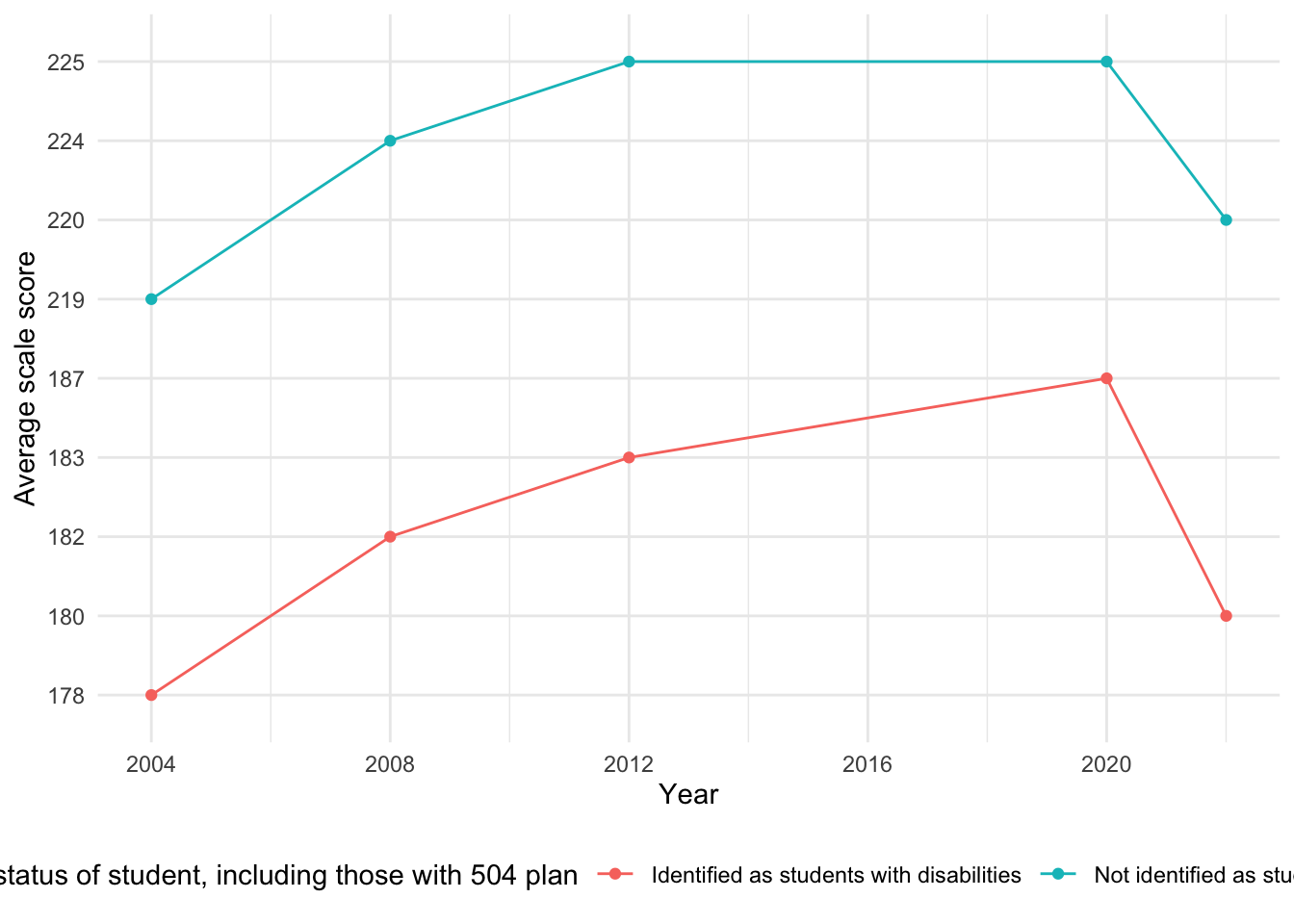
[1] "Total number of missing values in the disability_r dataset: 2"Just like the mathematics data, data is missing for 2016 for the disability variable and for most other variables. Other than that, data is collected roughly every four years, with the exception of data in 2022 after 2020. We assume a national assessment was conducted in 2022 to evaluate student learning during the pandemic.
The 2004 data appears in two forms: one marked as valid and another flagged as ‘Original assessment format.’ The flagged data has missing scores (noted as ‘‡’), likely due to differences in assessment methodology during a transition year. This analysis includes only the standardized scores for 2004 and excludes flagged data to maintain consistency.
2.2.2.2 Gender
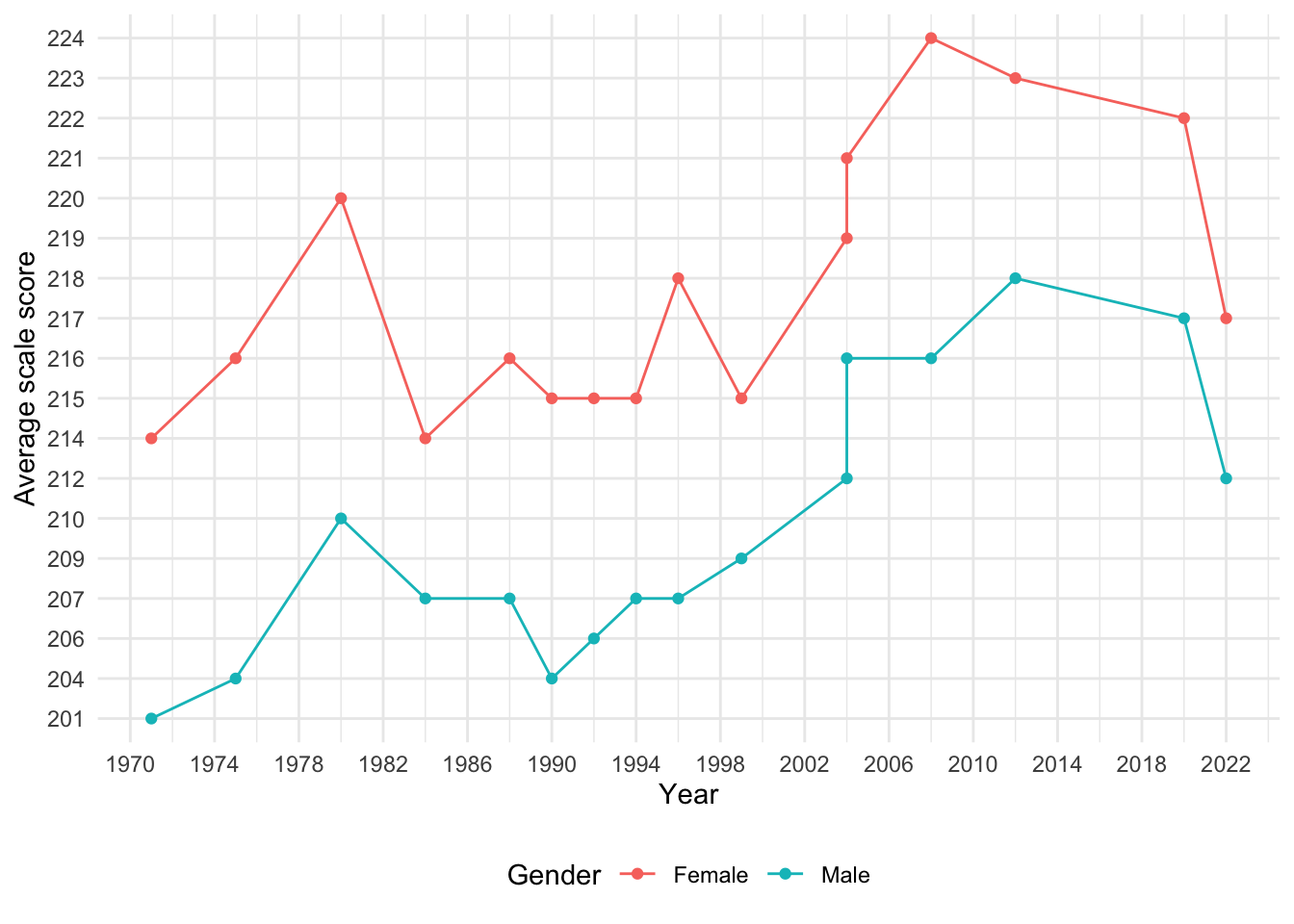
Once again, there is data for every 4 years starting from 2004, with the exceptions of missing 2016 data and data in 2022, just two years after data was collected for 2020. The dataset does not include any flagged entries indicating that reporting standards were met for all listed years.
2.2.2.3 National School Lunch Program
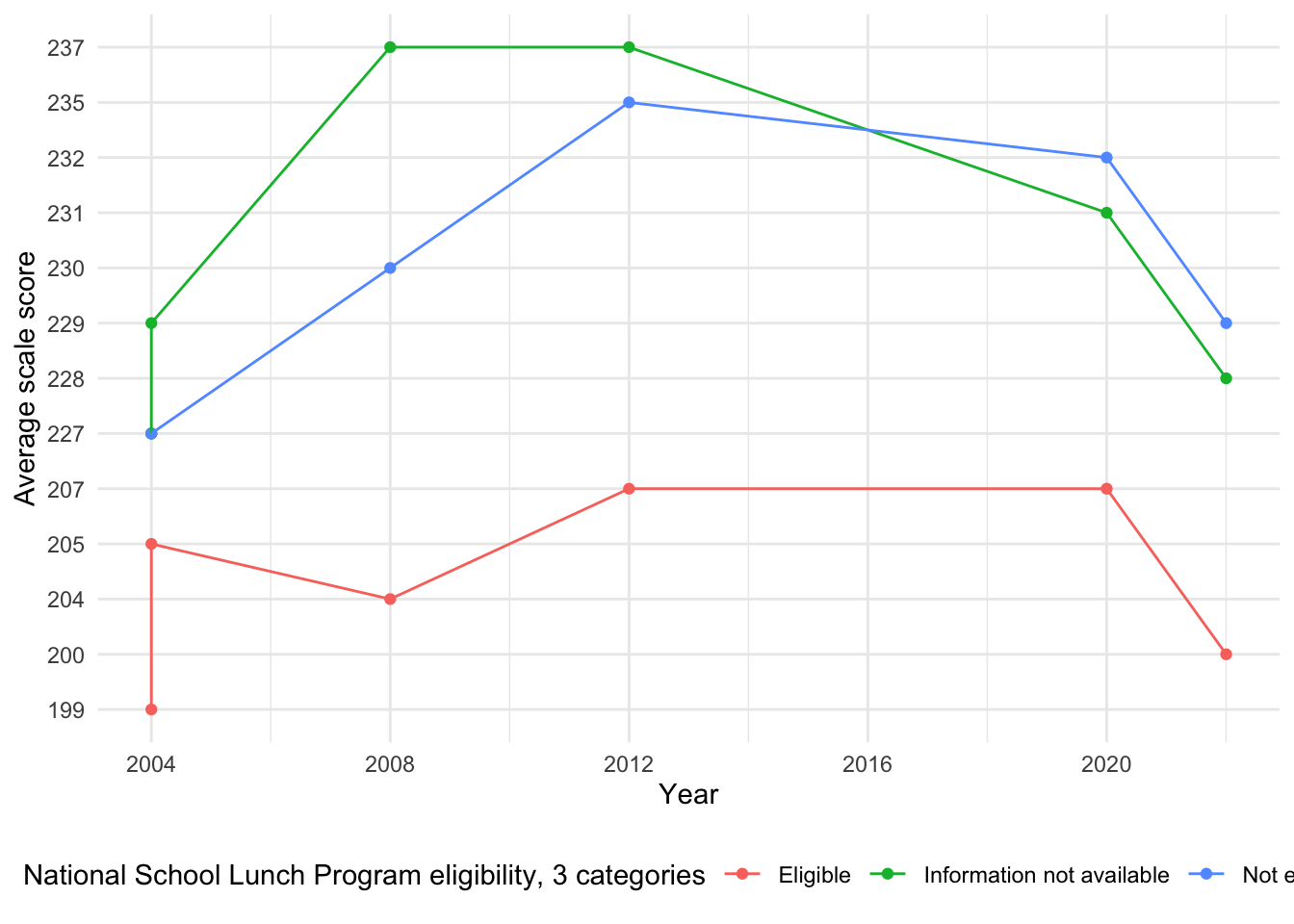
[1] "Total number of missing values in the lunch program dataset: 30"Again, starting every 4 years from 2004, data is only missing for 2016.
This data includes 30 flagged entries (-) from 1971-1999, indicating that information is not available. These were excluded from the analysis.
2.2.2.4 Race Ethnicity
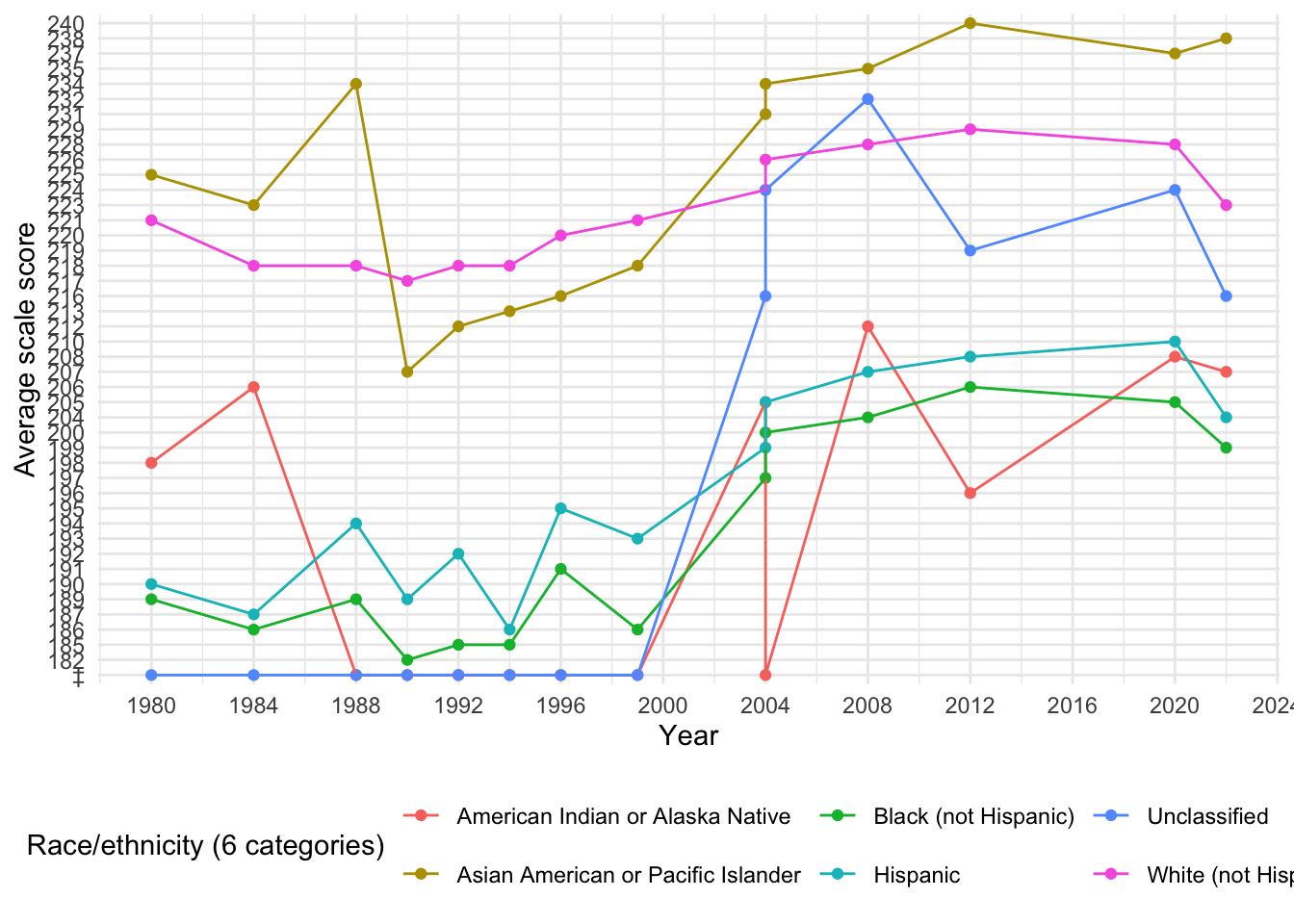
[1] "Total number of missing values in the race dataset: 15"Similar to the graph for mathematics data for race, the special characters indicating missing values appear at the bottom of the y axis. Data is missing again 2016. There are 15 missing score entries in this dataset, mainly (‡) values. These are most commonly seen for “American Indian or Alaska Native” and “Unclassified” categories, likely due to insufficient sample sizes.
2.2.2.5 School Region
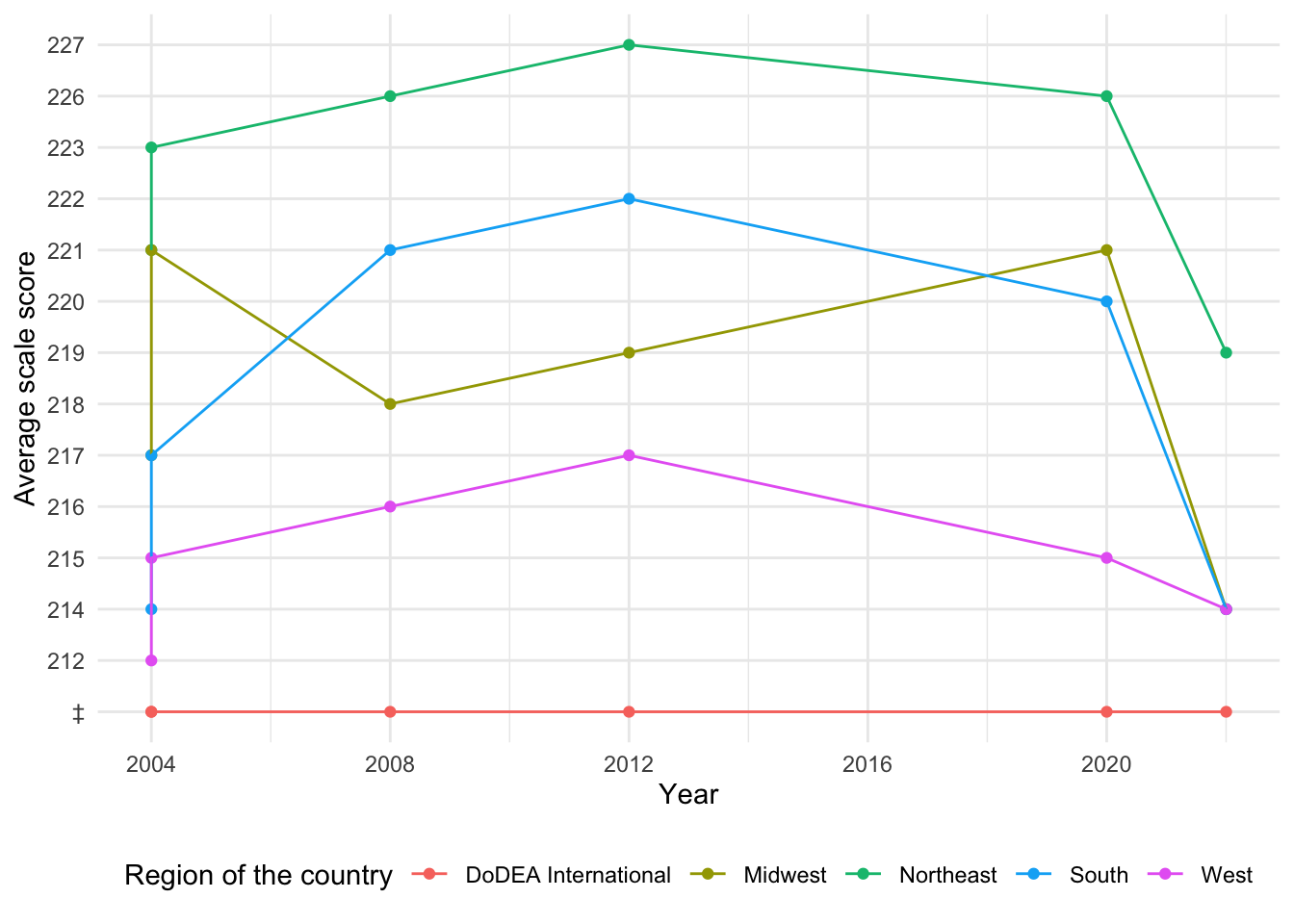
[1] "Total number of missing values in the region dataset: 56"Interestingly here, the ‘DoDEA International’ category has fully missing data, as we can see from the special character on the y axis mapping to that category for every year. As this is also the case for the mathematics data, including this cateogory will probably not be helpful in our analysis. Data for 2016 is missing again.
The dataset contains two types of missing values for the Average scale score column: the special characters “—” and “‡”. Both represent missing data and are not included in the analysis.
2.2.2.6 School Location
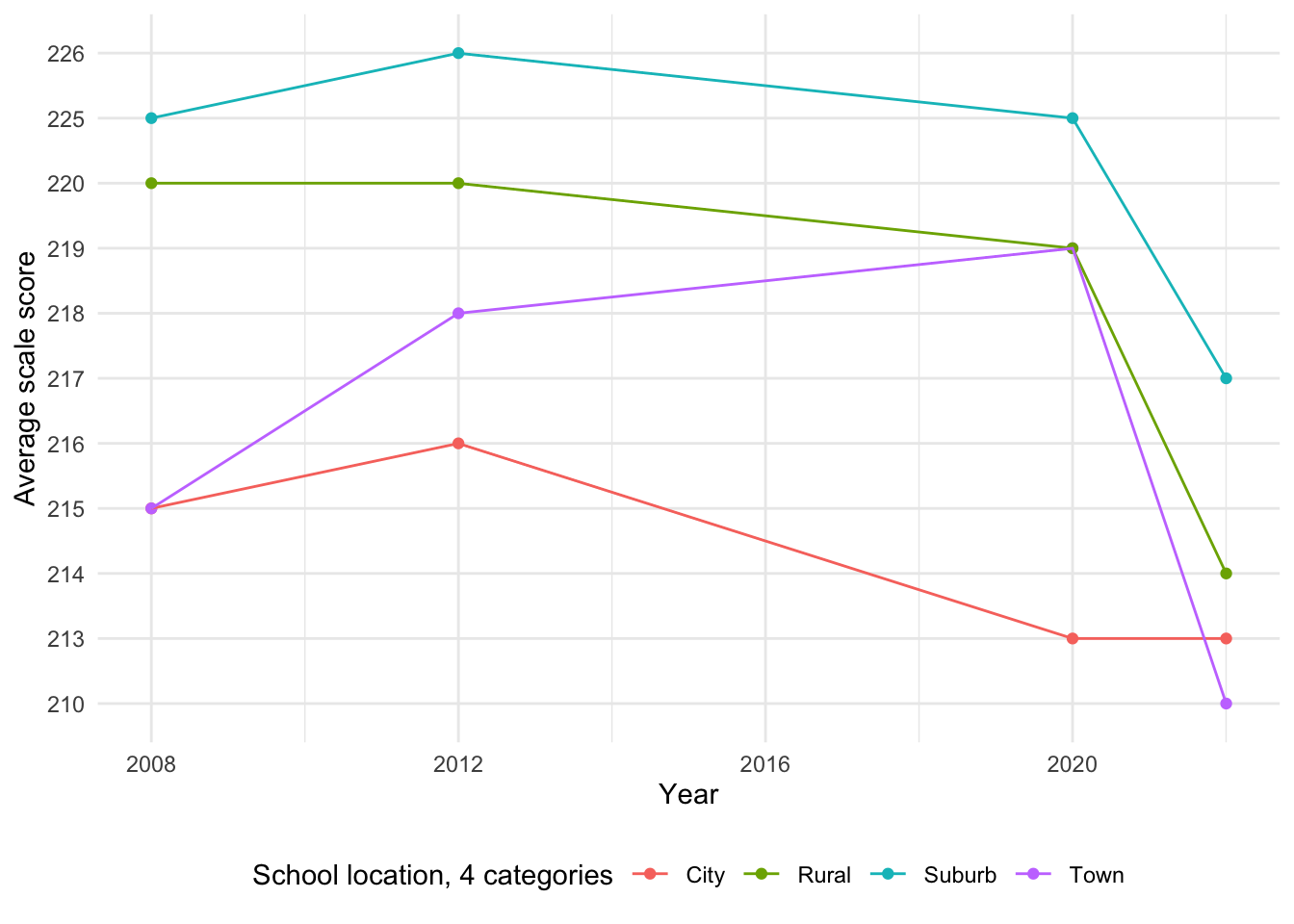
[1] "Total number of missing values in the location dataset: 48"Unlike some previous variables, data for this variable is missing for 2004 as well as 2016. There are 48 missing values in the Average scale score column starting for earlier years including 1971-2004. #### Status as English Learner
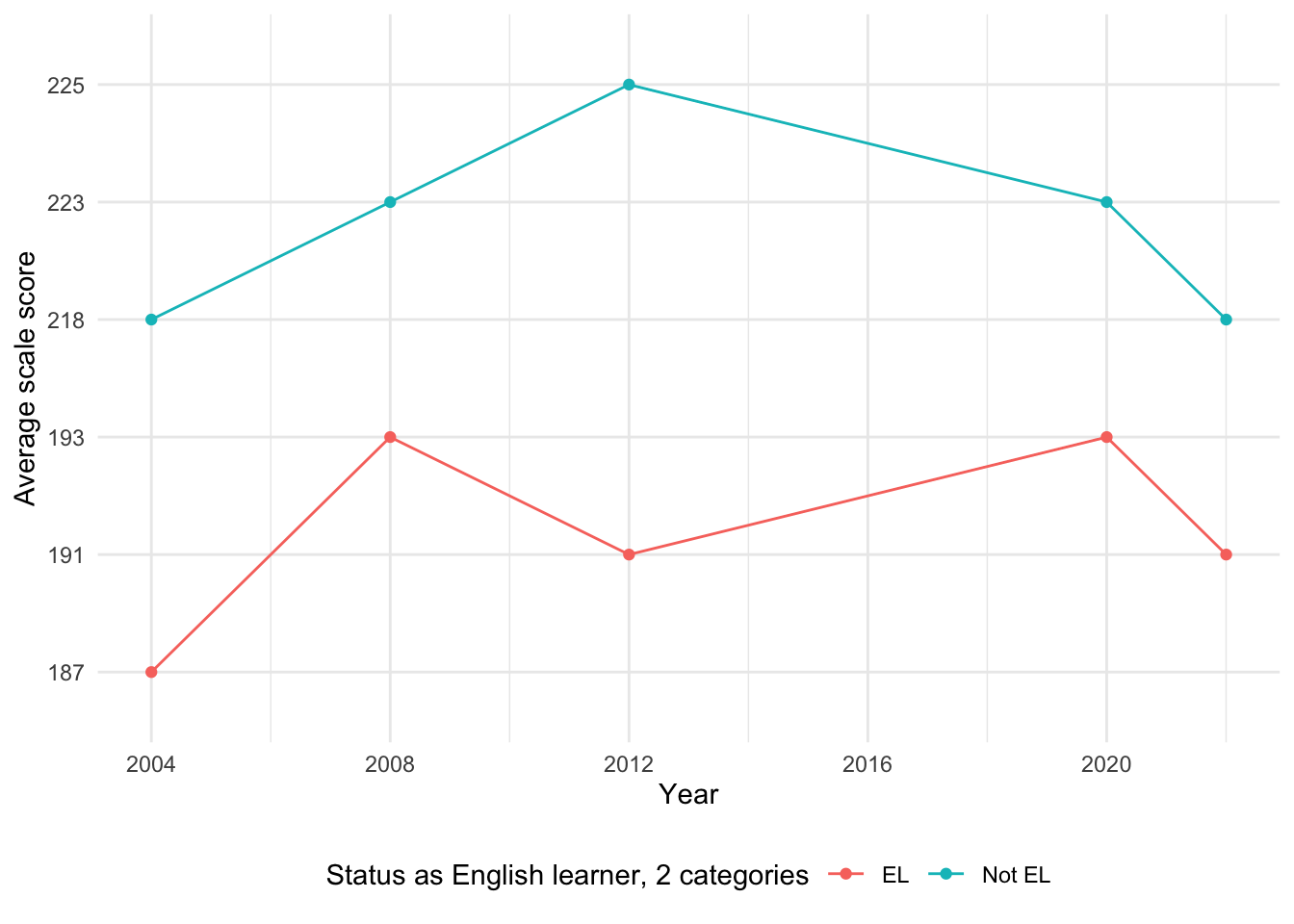
[1] "Total number of missing values in the English Status dataset: 22"Data is missing only for 2016. A total of 22 missing average scale score values exist in the dataset, and these gaps mostly correspond to earlier years where data might not have been reported or was unavailable.
Overall, the data availability across these datasets is generally strong, with most datasets exhibiting consistent reporting over multiple years. Missing values are typically encountered in earlier years suggesting that data collection methods or reporting standards may not have been as consistent in those periods.
Some datasets, like the gender or region datasets, show almost complete data coverage, while others (e.g., the 2016 year in some datasets) have isolated instances of missing values. In general, the data is reliable for trend analysis, though attention must be given to specific years or categories with missing values to ensure proper handling in analyses.